En los últimos tres años, los modelos de inteligencia artificial (IA) han experimentado avances significativos. Actualizaciones recientes de herramientas como ChatGPT, Claude, Gemini o DeepSeek ofrecen respuestas convincentes a diversas consultas. Sin embargo, la primera respuesta generada por estos modelos no suele ser la más adecuada, lo que puede llevar a una subutilización de su potencial.
Una estrategia efectiva para optimizar los resultados es encadenar varios modelos de IA, permitiendo que cada uno refine el trabajo del anterior. Cuando se solicita algo a un modelo de IA, este genera una respuesta basada en el contexto proporcionado. Si el contexto es limitado, la respuesta resultante será mejorable. Por otro lado, si el contexto es adecuado pero la solicitud es amplia, la IA puede ofrecer una respuesta razonable, aunque sin profundizar en aspectos específicos.
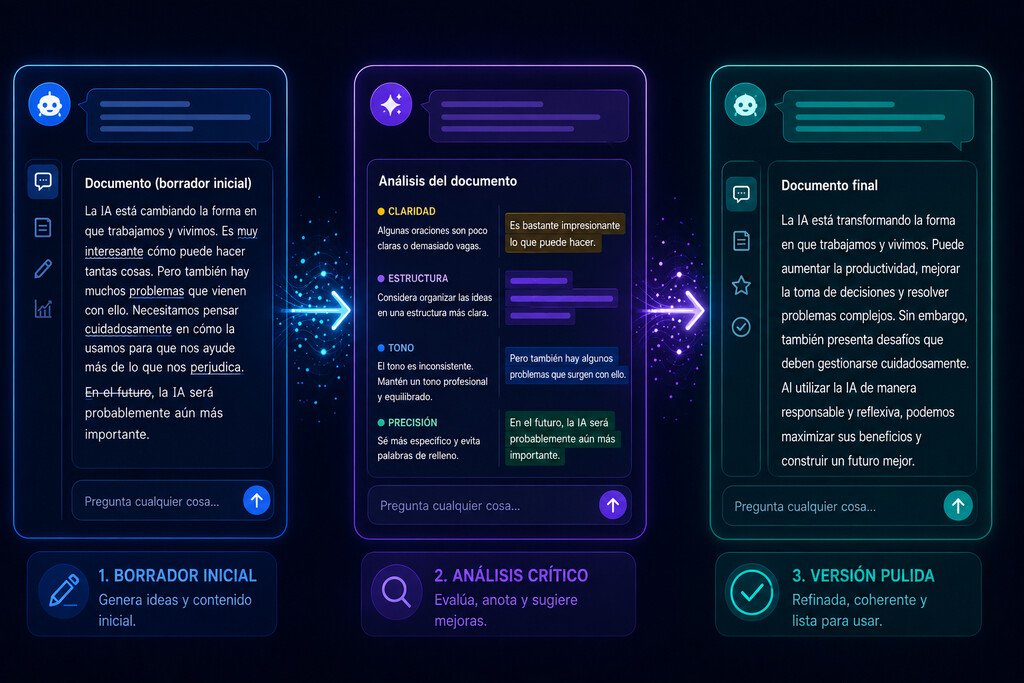
El encadenamiento de modelos de IA implica utilizar la salida de un modelo como entrada para el siguiente. En lugar de solicitar a una IA que realice todo en un solo paso, se puede dividir el trabajo en varias fases. Así, un modelo genera un primer resultado, otro lo critica, un tercero lo refina y un último lo verifica. Cada modelo asume un rol especializado, lo que mejora la calidad del resultado final.
Es fundamental considerar que los modelos de lenguaje responden al contexto inmediato que reciben. Un modelo que se dedica exclusivamente a criticar un texto es más eficaz que uno que intenta generar y criticar al mismo tiempo. La especialización en cada fase del proceso contribuye a un mejor resultado.
Para ilustrar esta estrategia, se puede considerar el ejemplo de redactar un correo electrónico para rechazar una propuesta de colaboración sin dañar la relación profesional. Se podría pedir a ChatGPT que redacte un correo con ciertas características. Aunque el resultado inicial sea válido, se puede mejorar al pasar el texto a Claude para que identifique sus puntos débiles y sugiera mejoras. Posteriormente, se puede refinar el texto con otro modelo, como Gemini o ChatGPT, incorporando las sugerencias realizadas.
Este proceso de encadenamiento puede transformar un resultado aceptable en uno de calidad superior. Aunque no es necesario utilizar varios modelos de IA, también se puede aplicar la misma estrategia con un único modelo, variando el enfoque en cada mensaje. La clave es no solicitar a un único prompt que realice todas las tareas, sino dividir el trabajo en fases de generación, crítica y refinamiento. Cada paso adicional puede aportar beneficios significativos en la calidad del resultado final.




